HadokeMDP
HadokeMDP is a Reinforcement Learning algorithm that use Q-learning in a discrete environment to play a custom StreetFighter game. And win.
HadokeMDP
![]()
HadokeMDP is a Reinforcement Learning algorithm that use Q-learning in a discrete environment to play a custom StreetFighter game. And win.
HadokeMDP
HadokeMDP is my first attempt to design a Reinforcement Learning AI.
I used the classical StreetFighter combat system as the AI environment.
Just a bit redesigned :)

Ryu against Ryu, who will win? :D
In a school seminar, we had the opportunity to make a presentation about the AI topic we wanted.
Only a powerpoint was needed, so I decided to create a game, as the Reinforcement Learning field really passionate me !
The environment : The Game
Why a StreetFighter game ?
Before designing an AI, we absolutely need an environment into which we can test it.
After some reading about the Reinforcement Learning (RL) topic, I decided that a game such as StreetFighter would be a great environment. This is
because the number of possible states seems "kinda small" and as is the number of inputs. I didn't wanted to focus on optimisation too much for this
first attempt but solely on the heart of the algorithm itself. Of course those kind of algorithm are a lot about optimisation, but the main goal
for me was to understand and training myself. And I knew AlphaGo or AlphaStar challenges was kinda out of scope, for now ;)
How does this game works ?
As I said, the finite numbers of state was a real need for my algorithm to work properly. So instead of associating each attacks with frame durations
(ex: the punch duration is 240ms/8frames) I decided that I would break down attacks into unique but longer frames (0.5s) !
Here is how an attack works :
- Arming phase : one frame for starting an attack, during this frame the character is harmless.
- Activate phase : one frame for dammaging the oponent if he is in the attack zone.
- Disarming phase : one frame where we go back to the idle state, during this frame the character is harmless too.
Of courses there will be some variations, but this was the heart of the concept.
What's more, I wanted to create some kind of "Rock Paper Scissor" metagame, just in order to create some depth to this game. This depth was somewhat
vital to my tests as I really wanted my AI to discover the bests strategies by itself <3
As simplicity is the supreme sophistication, I only created one fast punch, one ranged kick and one powerful uppercut. Oh and I also created a guard that
can block any attacks but the uppercut !
Oh ! And when we are hit, we need 1 frame to recover too ! :)
Here is a diagram of the state machine of the game :
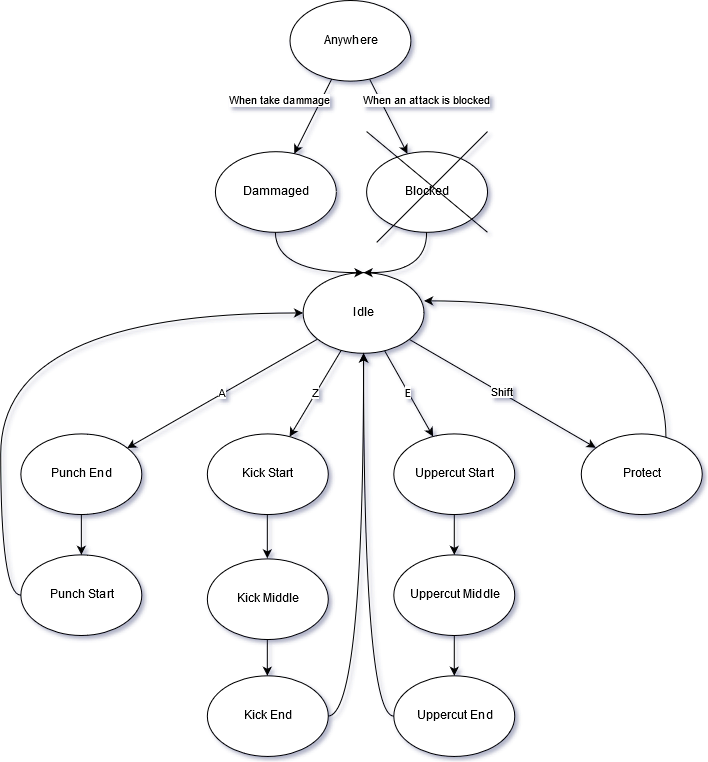
As you can see, Kick and Uppercut both take 2 frames long to arm, but they are stronger attacks.
The Reinforcement Learning Algorithm
The first document that really catch my eyes was this one, I couldn't be more grateful to Leslie Pack Kaelbling, Michael L. Littman and Andrew W.
Moore for their paper which was really instructive. Even if it is as old as me !
So, how does this algorithm works ?
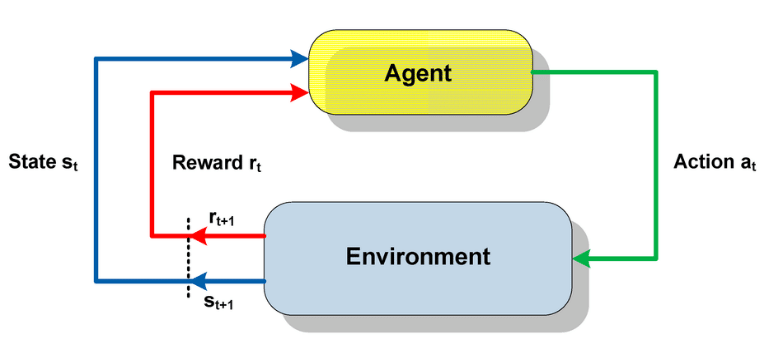
It's a Q-learning algorithm, which is part of the Reinforcement Learning algorithms. The main point of this category of algorithms is to make
the bot learn everything by itself, without ever telling him the rules of the game. That's why such algorithms as AlphaZero could solve both
Go and Chess on the same basis. The heart of the program is a loop that try an action and look for the reward we will give him. If the reward is positive, than the algorithm will be more inclined to take the same action again, if the reward is negative, than the algorithm will be less inclied to.
Here is the loop that is used in RL algorithms :
All actions are coupled to states of the game.
The same action in a different state could have a very different reward.
This is the main reason I wanted to keep the number of states low.
So we need to give rewards to our bot in order to tell him what we want him to do. But not how to do it, he will figure this all by itself !
We want him to win right ? Each bot have 10 lifes, so when the opponent life is reaching 0, we could reward him positively, but if he reaches 0 we
should reward him positively. This could be a good solution, however this doesn't guide our bot very well because we are giving him guildelines
very rarely, so it will learn slowly. In fact we know that in order to put the opponent life to 0 we need to hurt him, so we could have gave him
a reward for hurting his opponent or when he is hurt.
I think this is a dangerous approach. Indeed hurting the opponent is an absolutely necessity, but maybe positionning is even more important and if
we have a good positionning maybe there exists a perfect strategy until the win, even at 1 life against 10 ! Even if this is unlikely to happend
it's this kind of case that us, humans, don't always think about. And I think it is why AI can take an edge over us ! So I don't want my bot to be
private from this privilege !
As I don't want my results to be too slow but I don't want my bot to me too guided either, I chosed an in between policiy :
- when a bot wins he gains a reward of +10
- when a bot loses he "gains" a reward of -10
- when a bot hurts the opponent he gains a reward of +0.1
- when a bot is being hurt he "gains" a reward of -0.1
Here you can see that finaly, the bot is very rarely rewarded and that there are plenty of frames where he won't gain any reward, this is on purpose
as we want it to be able to develop his own strategy ! =)
You can find here a paper I wrote about this AI :
And here the presentation I gave for the seminar :
The results : beyond all expectations !
I won't be modest here, the results were just incredible and I didn't think it was even possible to reach such a level of mastering for an
AI with such simplicity !
I am not saying that I have done an amazing job, but rather that RL seems extremely promising to me.
Without training
Something that is really important to understand about Q-learning is that a bot (or his brain) starts without knowledge, and as he go he will
gather experience in what we name a Q-table. A Q-table is just a very large two dimensionnal array where one dimension represents states and the
other represents the actions possibles in this state. And at the intersection we have the score of this action in this state. The higher the score
the better it is for the bot to chose the associated action.
So when I started to make 2 bots without training opposing each other, they had rather randomized behavior that you can see here :

We can observe that the bots are acting very randomly, attacking when they are far away, and never blocking on the good timing.
They even pass some frames doing nothing ! ^^'
After 100 matches
The more the bot is trained, the more he need to make a choice : Should I use the action that I know have the better expected result, or should I try
another less optimal action in order to discover some potential better stregies ? This is the classical problem knowed as Exploitation versus
Exploration. In practice, I chosed an exploration_rate between 0 and 1 that starts very high and decreases when the bot is gaining experience.
This works exactly as a temperature in a lot of algorithms.
You can here observe the 2 bots after having practice 100 matches against each other :
We can observe that now the bots seems to have much more coherent actions, and that they are blocking at the right timing. This is a good
improvement !
However they are still progress to be made as they are still trying to send attacks when they are a bit far away, which is dangerous.
Don't worry of the speed up and down of the video, I am just doing this in order to gain time, it's not a speed up in computing or
any sort of bug.
We can sometimes observe loop in the patterns of the bots. I was first worried that they would loop forever, but as they are learning at the
same time as they are fighting and as their exploration_rate is never null, they will always try some new techniques if they are stuck in
non-rewarding loops. This is one of the beauty of this algorithm.
The results are 49% winrate for the left bot and 51% winrate for the right bot. Which seems pretty reasonnable ! :)
After 15000 matches
I let my computer running for one entire night. I was praying for no memory leak to happen or any issue like that ! And I was sooooooo happy
when I discover my 2 bots, left and right, still fighting in the morning !!! <3
Of course I had disable the display mode so they were only fighting virtualy at the speed of light, without the constraint of the 0.5s time
frame !
Each match was taking about 650ms :)
We can observe that now the bots have a clear strategy ! The right one is constantly moving left and right in order to push his opponent in
the corner !
Now positionning matter ! Because when you are cornered, you can't dodge by breaking the distance anymore ! <3
OK, but there is a problem here : the left bot have a winrate of 5%, the right one have a winrate of 90% and there is a 5% chance of tie !
How can we explain this ? Aren't they supposed to be the SAME BOT fighting against each other ???
I thought about it for a long time. And then I came to this conclusion : "My game is NOT balanced !" If the bots don't have the same behavior, it's
because the game isn't symetrical !
So I look into my code and I found the error. It was in the moving function. I was moving the left bot first, and then the right bot. This doesn's
seems to be much of an issue, but if both bot are in melee (as near as possible) then if the left one want to go back the right one can follow him !
And symetricaly, if the right one want to go back, the left one can not follow him ! This is a huge advantage ! Even if a human player could
struggle to capatilize on this very one asymmetricity, a bot could exploit it until winning every single match !
This is why I was so bluffed
by my AI. She just did found bugs in my algorithm and exploits it until having concrete results with !
AI > Humans
I tried several times to measure myself to my bot (the right one ^^'). And it was always the same result : I could't hurt it without being hurt
in respons ! Not even once !! And I don't think that I am too bad of a player to this game, as I crafted it :)
That's why I can say that my AI solve this tiny StreetFighter game and that no Human is capable of beatting it now.
And that's an incredible feeling. I know that it is irrelevan t as no-one ever play my game. But I can see the potential of this kind of
algorithm. They could be applied to so many games or real life problem that I wan't to dive into it more deeply ! :)
Here is a match of a 100 matches AI at the left, and a 15000 matches AI at the right, just to see the progression of the AI :

I bet on the right one ! ;)
We can see that this is a no-match.
Limitations of this algorithm
Even if I love this algorithm, it has an enormous weakness : it is extremely memory gluttonous. It's about O(A * S) where A is the number of actions
and S the number of possibles states of the game. In HadokeMDP I managed to minimize the size of the Q-table as much as 440 000, but it's still
enormous for a game of this simplicity. It wouldn't be scalable, at all ! The main issue being S which tends to explode when we add character or
expand the size of the map.
If this seems to condamn this beautiful algorithm (I am totaly objective, yes :p) to small problems, they are however some solutions !
One very good example is AlphaZero which is using a RL algorithm coupled with a Neural Network used to decrease the dimentions of the states and an
other one used to chose the the best action "inside the Q-table". I am quoting it because there isn't any Q-table anymore, but it's kind of the
same principle :)
Get In Touch
